背景
If you can't measure it, you can't manage it
在家庭服务器(homelab)日常维护过程中,时常会遇到磁盘打满、CPU占用过高、内存不足等问题。当这些问题出现时,往往较难排查,我决定搭建一个监控 + 报警系统。经过多次调试和 debug 后,我确认这套监控方案是低成本并有效的,因此将配置过程分享出来。
技术选型
1. Prometheus - 开源系统监控和警报工具包,使用非常广泛
2. Node Exporter - 硬件和内核相关的指标收集器
3. Grafana - 大名鼎鼎的数据可视化观测、监控平台
4. 飞书 Webhook - 报警接收器的一种实现,通过飞书机器人进行通知,当然你也可以使用 telegram、dingding
配置过程
首先确保机器上安装了 docker 和 docker-compose,新建配置文件 docker-compose.yml,并按以下步骤配置和启动服务,这个配置集成了 prometheus、node exporter 和 grafana,因此无需再手动安装任何依赖
version: "3.2"
services:
node_exporter:
image: quay.io/prometheus/node-exporter:v1.5.0 # 使用 node-exporter 镜像的 v1.5.0 版本
container_name: node_exporter # 容器名称为 node_exporter
command: "--path.rootfs=/host" # node-exporter 的启动命令,设置 root 文件系统路径
pid: host # 使用主机的 PID 命名空间
restart: unless-stopped # 设置容器除非手动停止,否则始终重启
ports:
- 9100:9100 # 将容器的 9100 端口映射到主机的 9100 端口
volumes:
- /:/host:ro,rslave # 挂载主机根目录到容器,只读且使用 rslave 模式
grafana:
image: grafana/grafana-oss:latest # 使用 grafana-oss 最新版本镜像
container_name: grafana # 容器名称为 grafana
ports:
- "4000:3000" # 将容器的 3000 端口映射到主机的 4000 端口
volumes:
- ./grafana-data:/var/lib/grafana # 挂载宿主机目录到容器中的数据目录
restart: unless-stopped # 设置容器除非手动停止,否则始终重启
prometheus:
image: prom/prometheus:v2.37.9 # 使用 prometheus 镜像的 v2.37.9 版本
container_name: prometheus # 容器名称为 prometheus
ports:
- 9090:9090 # 将容器的 9090 端口映射到主机的 9090 端口
command: "--config.file=/etc/prometheus/prometheus.yaml" # 启动时加载指定的配置文件
volumes:
- 你的路径/prometheus/config.yaml:/etc/prometheus/prometheus.yaml:ro # 挂载宿主机的配置文件到容器,只读
- 你的路径/prometheus/data:/prometheus # 挂载宿主机的数据目录到容器
restart: unless-stopped # 设置容器除非手动停止,否则始终重启
启动服务
在存放 docker-compose.yml 文件的目录中执行 docker-compose up -d ,这个命令会启动所有服务
配置 Grafana 看板
访问
http://<你的服务器地址>:4000进入 Grafana 界面,默认端口为 4000,首次登录时,账号密码都是 admin登录后添加 Prometheus 数据源,URL 填写
http://prometheus:9090


- 数据源配置完毕后,进入看板配置页面

- 导入社区的 Dashboard,这里我使用了下载数量最多的 1860 号模板

- 完成配置后,你应该可以看到一个精美的监控看板

配置飞书 Webhook
你也可以按照官方 飞书 Webhook 配置教程 进行配置
Webhook 又叫“网络钩子”,是应用给其它应用提供实时信息的一种方式。通过 Webhook ,可以在收到 HTTPS 请求时,自动触发流程运行。飞书机器人助手 提供 Webhook 触发能力,你可以通过 Webhook 将 Grafana 与 飞书机器人助手 连接起来。通过 Webhook,无需代码编辑,就可以实现从其他应用或服务自动接收数据。
- 访问飞书机器人配置网页,点击「新建指令」

- 点击「选择触发器」,选择「Grafana 新报警产生」

- 复制「webhook 地址」,后续我们配置 grafana 报警联系人时会用到

- 点击「选择操作」,将其设置为「通过官方机器人发消息」

- 在弹出的面板中,点击 「+」按钮,依次配置 grafana 的标题、状态、消息插槽,点击完成后发布即可

- 至此我们已经有了一个飞书 webhook 机器人,下一步我们将配置 Grafana 报警规则

配置 Grafana 报警联系人
- 首先进入 Grafana 的报警联系人控制面板中,选择 「contact point」对报警联系人进行配置

点击编辑,对报警配置进行修改
这里我直接修改默认的报警联系人,当然你也可以新建一个,后续报警配置会略有不同

- 录入前面我们复制下来的 webhook 地址,点击保存即可

- 测试一下,确保链路正常

配置 Grafana 报警规则
这一步的进阶配置需要你对 bosun 或者 PromQL 语法有一定了解,如果你不了解 bosun 语法也没有关系,可以直接复刻我的温度报警配置
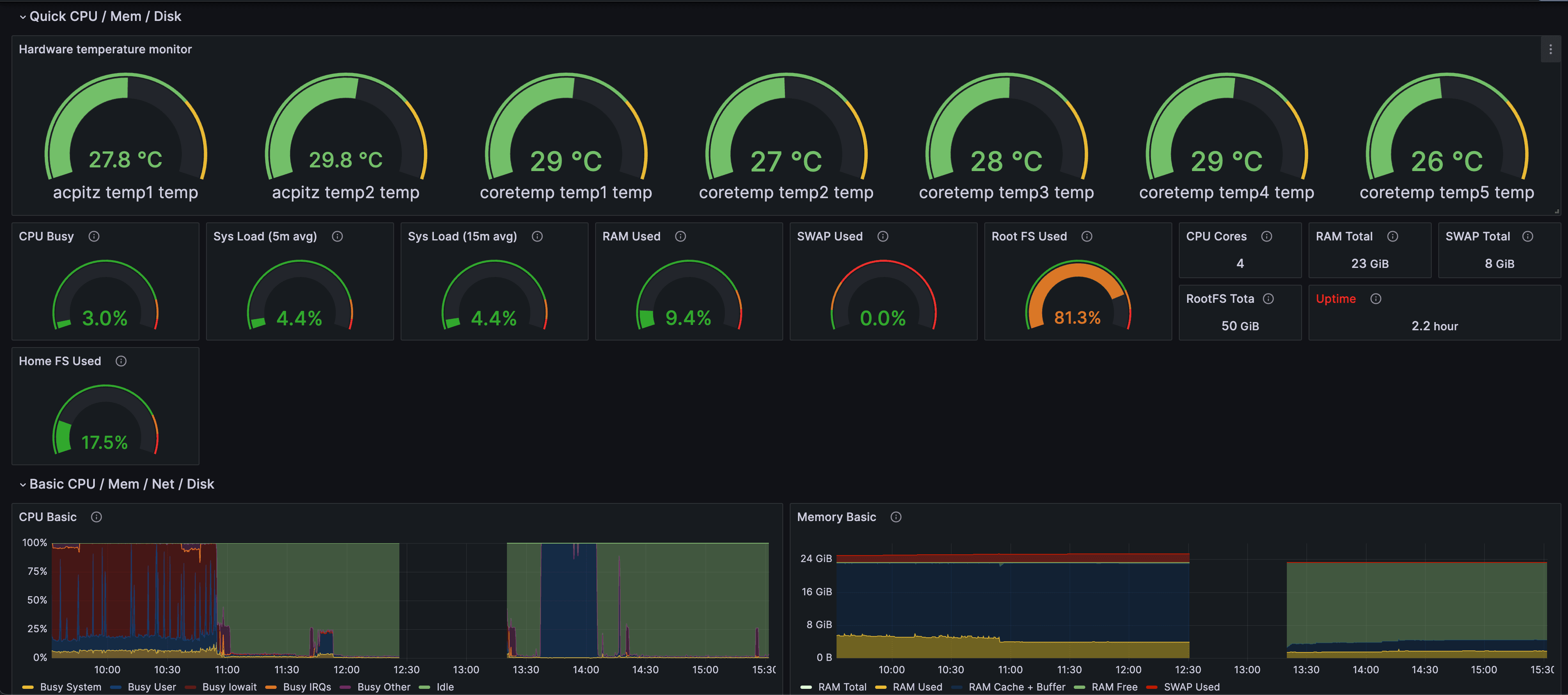
- 进入 Grafana 监控面板,找到带有你需要监控的指标的面板,对它进行编辑,这里我选中了硬件温度监控面板(Hardware temperature monitor)

- 进入面板编辑区域,选中报警配置 Tab(Alert),我们尝试新建一个报警规则

按照图中的步骤配置报警规则,这一步需要消耗一些时间,首次配置请耐心
如果你对于指标的配置存在疑问,可以将所有指标删除后,将下面这个查询语句粘贴到第二步的输入框中
node_hwmon_temp_celsius{instance="node_exporter:9100",job="node_exporter",chip="platform_coretemp_0"} * on(chip) group_left(chip_name) node_hwmon_chip_names

- 继续配置,将报警规则添加到报警组中,并添加一些额外注解,方便接收报警时,快速了解如何应对

- 至此,我们完成了一项温度报警配置,如果你有兴趣了解 PromQL 语法,还可以继续配置磁盘利用率报警、内存利用率报警、丢包率报警等一系列规则
希望这篇文章对你有所帮助